21 Inference for comparing paired means
In Chapter 20 analysis was done to compare the average population value across two different groups. Recall that one of the important conditions in doing a two-sample analysis is that the two groups are independent. Here, independence across groups means that knowledge of the observations in one group does not change what we would expect to happen in the other group. But what happens if the groups are dependent? Sometimes dependency is not something that can be addressed through a statistical method. However, a particular dependency, pairing, can be modeled quite effectively using many of the same tools we have already covered in this text.
Paired data represent a particular type of experimental structure where the analysis is somewhat akin to a one-sample analysis (see Chapter 19) but has other features that resemble a two-sample analysis (see Chapter 20). As with a two-sample analysis, quantitative measurements are made on each of two different levels of the explanatory variable. However, because the observational unit is paired across the two groups, the two measurements are subtracted such that only the difference is retained. Table 21.1 presents some examples of studies where paired designs were implemented.
| Observational unit | Comparison groups | Measurement | Value of interest |
|---|---|---|---|
| Car | Smooth Turn vs Quick Spin | amount of tire tread after 1,000 miles | difference in tread |
| Textbook | UCLA vs Amazon | price of new text | difference in price |
| Individual person | Pre-course vs Post-course | exam score | difference in score |
Paired data.
Two sets of observations are paired if each observation in one set has a special correspondence or connection with exactly one observation in the other dataset.
It is worth noting that if mathematical modeling is chosen as the analysis tool, paired data inference on the difference in measurements will be identical to the one-sample mathematical techniques described in Chapter 19. However, recall from Chapter 19 that with pure one-sample data, the computational tools for hypothesis testing are not easy to implement and were not presented (although the bootstrap was presented as a computational approach for constructing a one sample confidence interval). With paired data, the randomization test fits nicely with the structure of the experiment and is presented here.
21.1 Randomization test for the mean paired difference
Consider an experiment done to measure whether tire brand Smooth Turn or tire brand Quick Spin has longer tread wear (in cm). That is, after 1,000 miles on a car, which brand of tires has more tread, on average?
21.1.1 Observed data
The observed data represent 25 tread measurements (in cm) taken on 25 tires of Smooth Turn and 25 tires of Quick Spin. The study used a total of 25 cars, so on each car, one tire was of Smooth Turn and one was of Quick Spin. Figure 21.1 presents the observed data, calculations on tread remaining (in cm).
The Smooth Turn manufacturer looks at the box plot and says:
Clearly the tread on Smooth Turn tires is higher, on average, than the tread on Quick Spin tires after 1,000 miles of driving.
The Quick Spin manufacturer is skeptical and retorts:
But with only 25 cars, it seems that the variability in road conditions (sometimes one tire hits a pothole, etc.) could be what leads to the small difference in average tread amount.
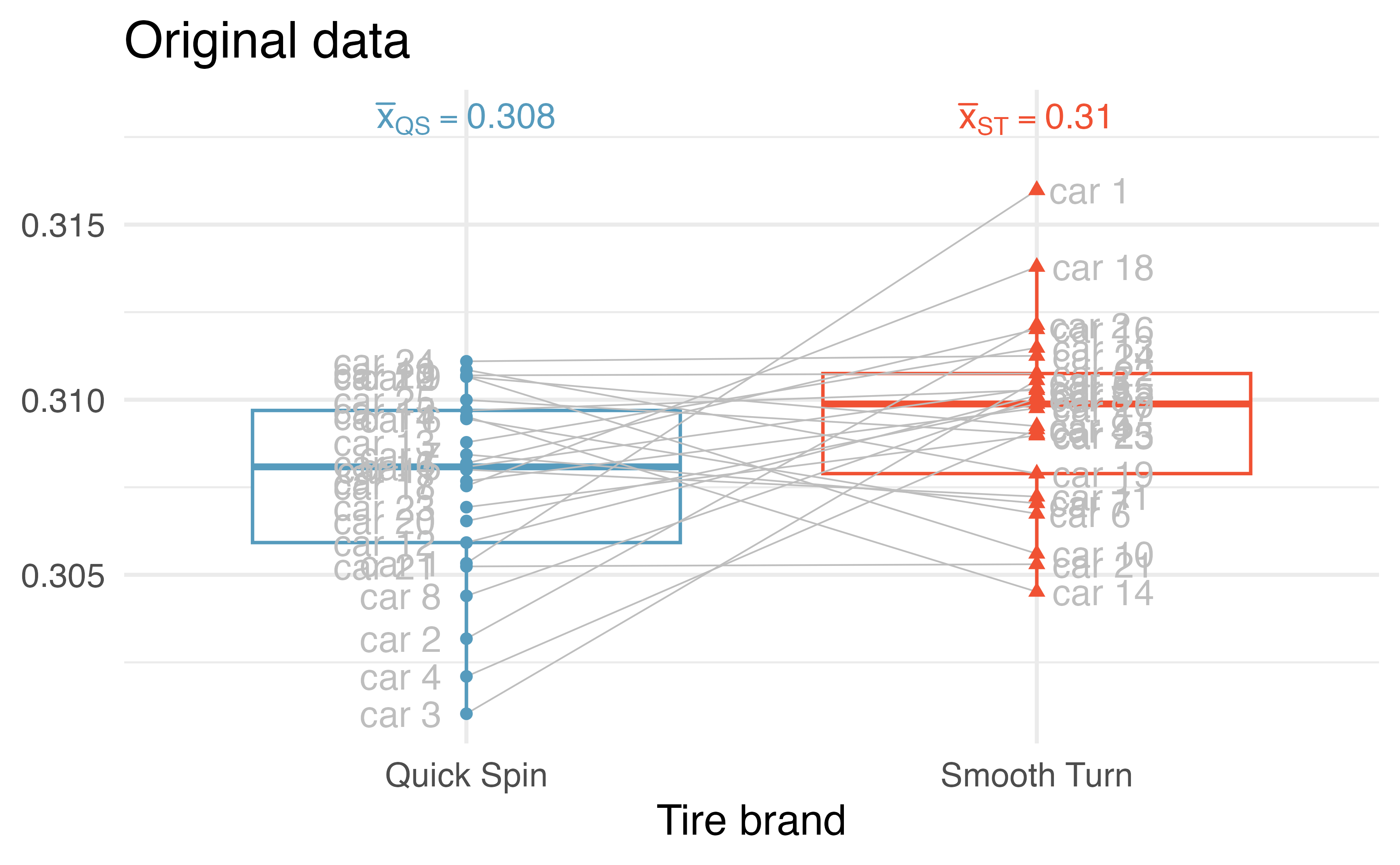
Figure 21.1: Boxplots of the tire tread data (in cm) and the brand of tire from which the original measurements came.
We’d like to be able to systematically distinguish between what the Smooth Turn manufacturer sees in the plot and what the Quick Spin manufacturer sees in the plot. Fortunately for us, we have an excellent way to simulate the natural variability (from road conditions, etc.) that can lead to tires being worn at different rates.
21.1.2 Variability of the statistic
A randomization test will identify whether the differences seen in the box plot of the original data in Figure 21.1 could have happened just by chance variability. As before, we will simulate the variability in the study under the assumption that the null hypothesis is true. In this study, the null hypothesis is that average tire tread wear is the same across Smooth Turn and Quick Spin tires.
- \(H_0: \mu_{diff} = 0,\) the average tread wear is the same for the two tire brands.
- \(H_A: \mu_{diff} \ne 0,\) the average tread wear is different across the two tire brands.
When observations are paired, the randomization process randomly assigns the tire brand to each of the observed tread values. Note that in the randomization test for the two-sample mean setting (see Section 20.1) the explanatory variable was also randomly assigned to the responses. The change in the paired setting, however, is that the assignment happens within an observational unit (here, a car). Remember, if the null hypothesis is true, it will not matter which brand is put on which tire because the overall tread wear will be the same across pairs.
Figures 21.2 and 21.3 show that the random assignment of group (tire brand) happens within a single car. That is, every single car will still have one tire of each type. In the first randomization, it just so happens that the 4th car’s tire brands were swapped and the 5th car’s tire brands were not swapped.
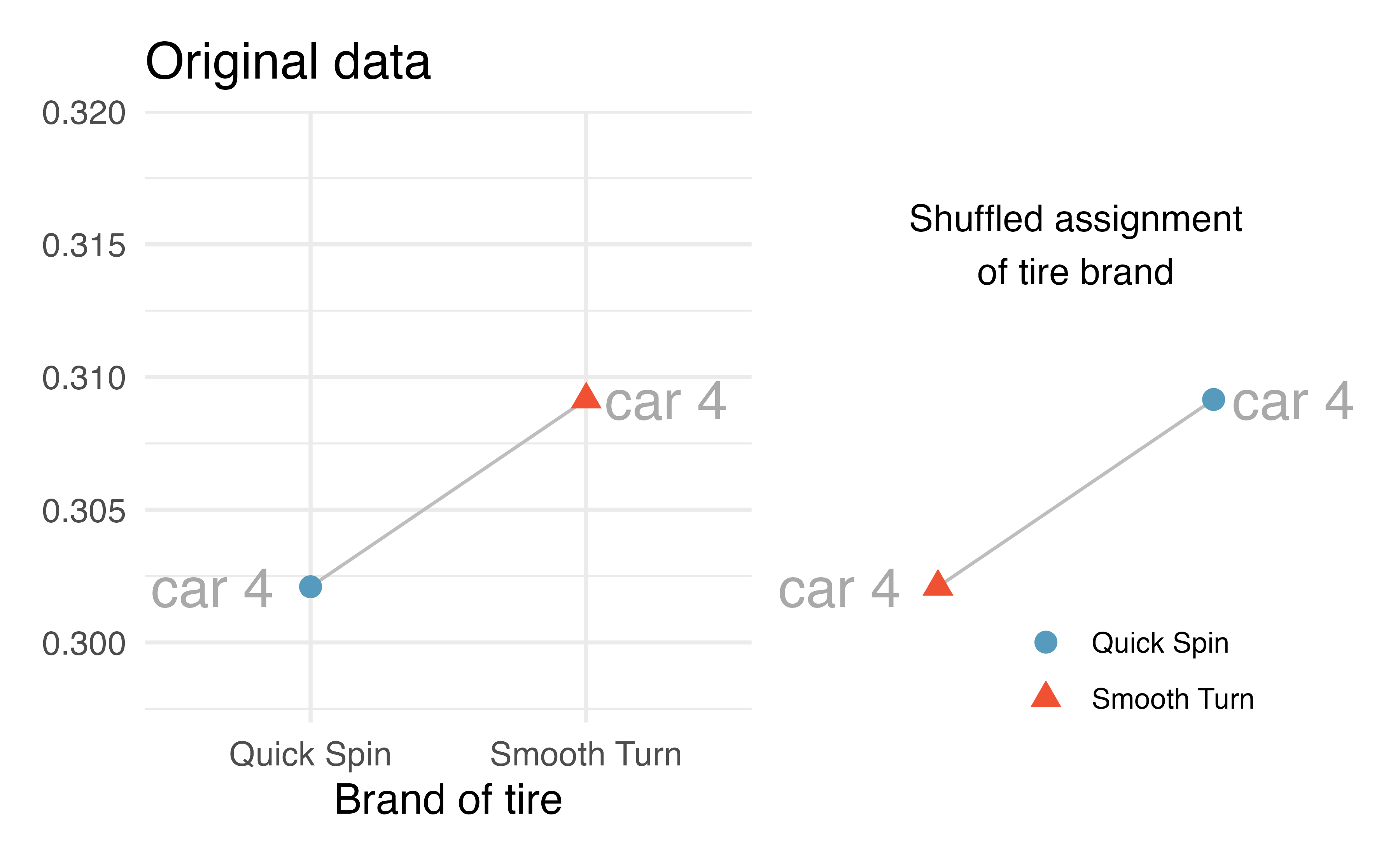
Figure 21.2: The 4th car: the tire brand was randomly permuted, and in the randomization calculation, the measurements (in cm) ended up in different groups.
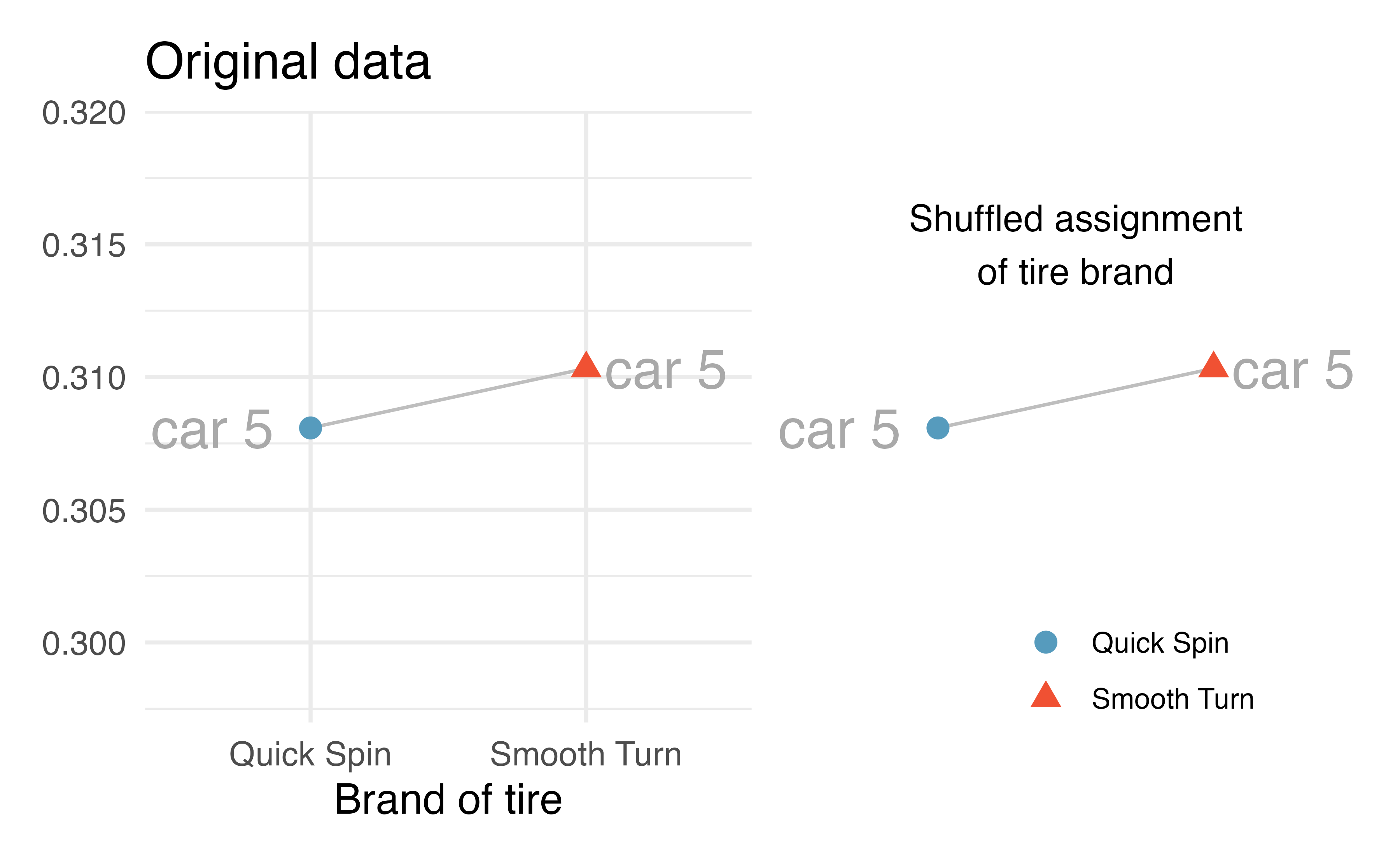
Figure 21.3: The 5th car: the tire brand was randomly permuted to stay the same! In the randomization calculation, the measurements (in cm) ended up in the original groups.
We can put the shuffled assignments for all the cars into one plot as seen in Figure 21.4.
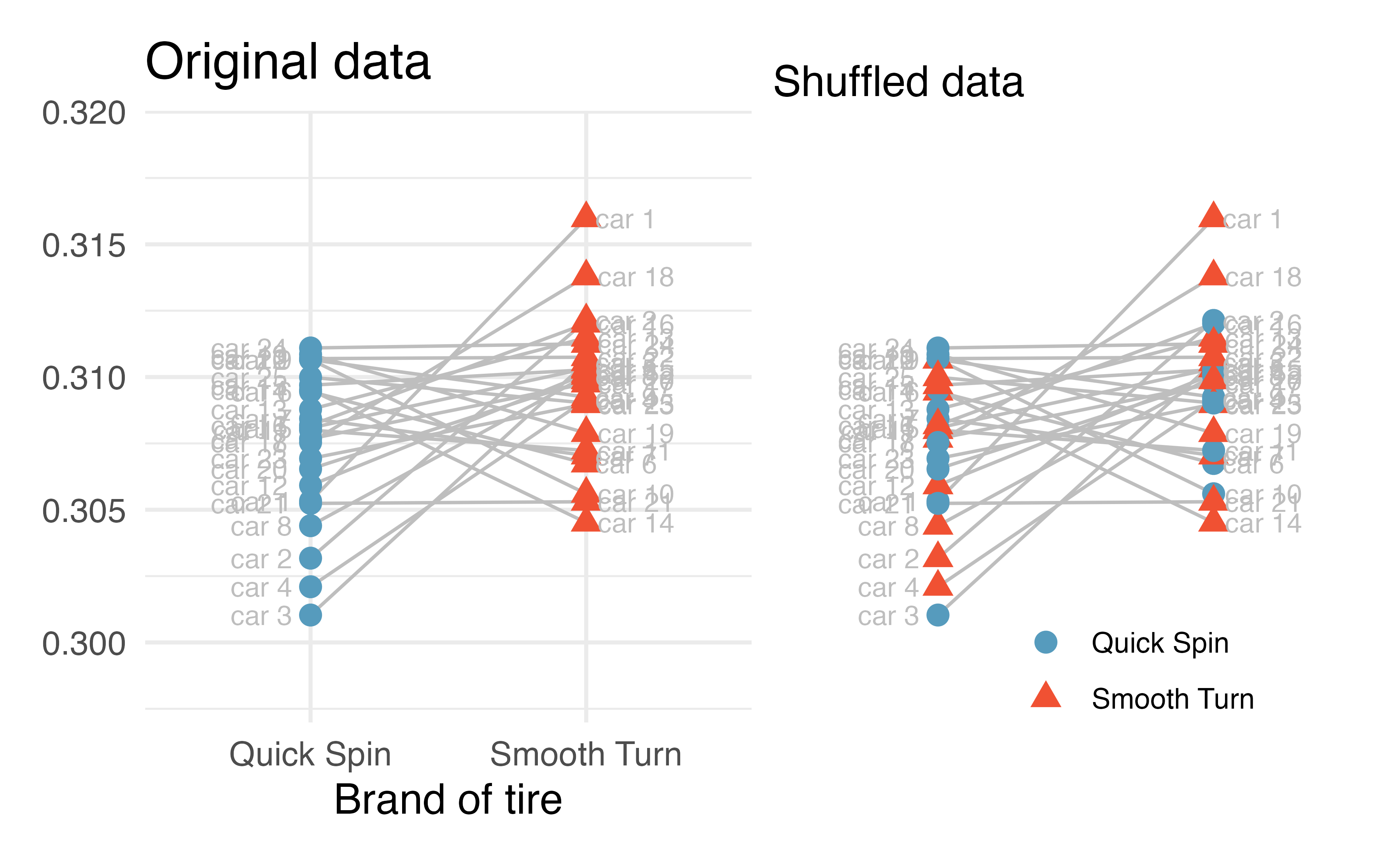
Figure 21.4: Tire tread data (in cm) with: the brand of tire from which the original measurements came (left) and shuffled brand assignment (right). As evidenced by the colors, some of the cars kept their original tire assignments and some cars swapped the tire assignments.
The next step in the randomization test is to sort the brands so that the assigned brand value on the x-axis aligns with the assigned group from the randomization. See Figure 21.5 which has the same randomized groups (right image in Figure 21.4 and left image in Figure 21.5) as seen previously. However, the right image in Figure 21.5 sorts the randomized groups so that we can measure the variability across groups as compared to the variability within groups.
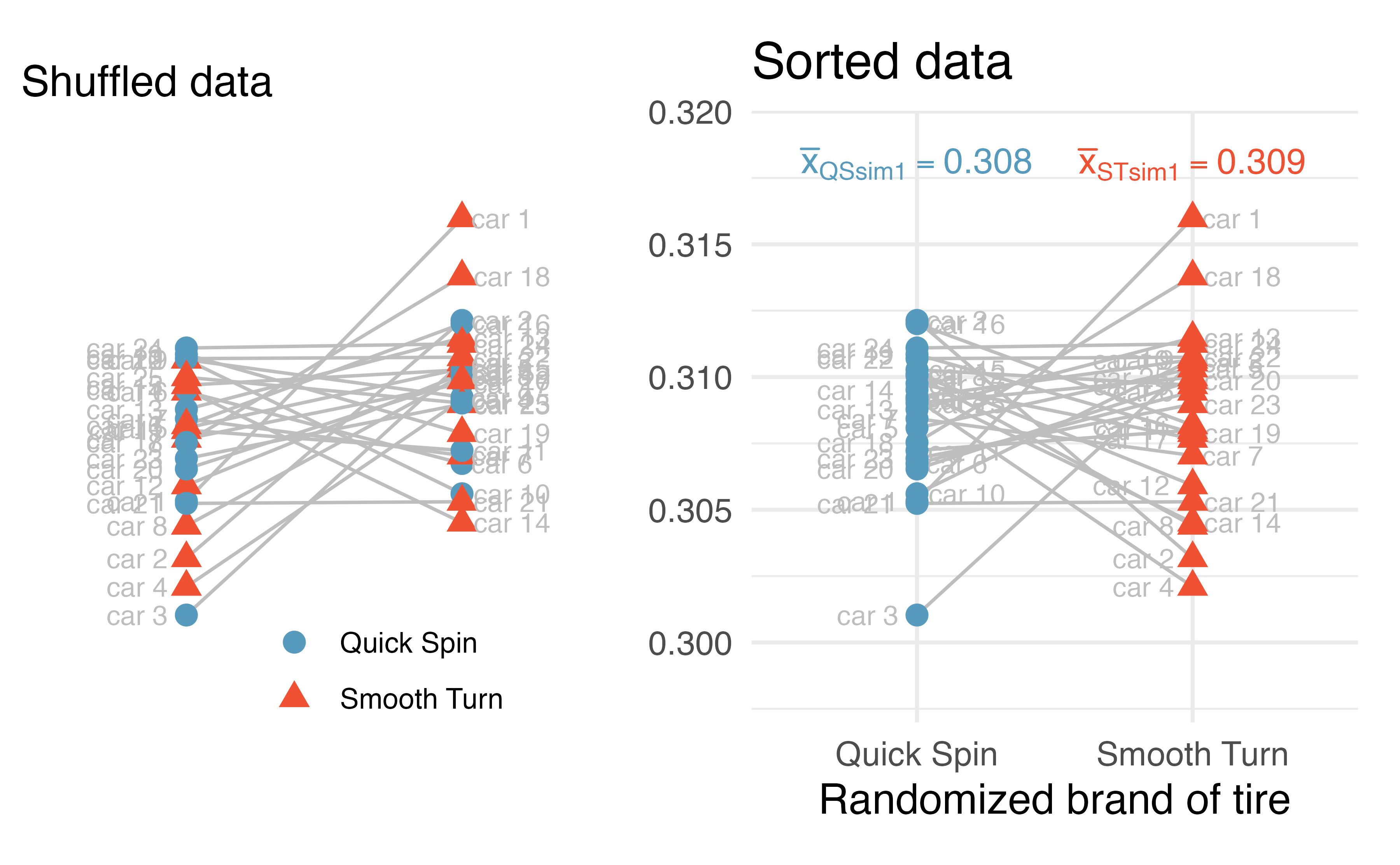
Figure 21.5: Tire tread from (left) randomized brand assignment, (right) sorted by randomized brand.
Figure 21.6 presents a second randomization of the data. Notice how the two observations from the same car are linked by a grey line; some of the tread values have been randomly assigned to the opposite tire brand than they were originally (while some are still connected to their original tire brands).
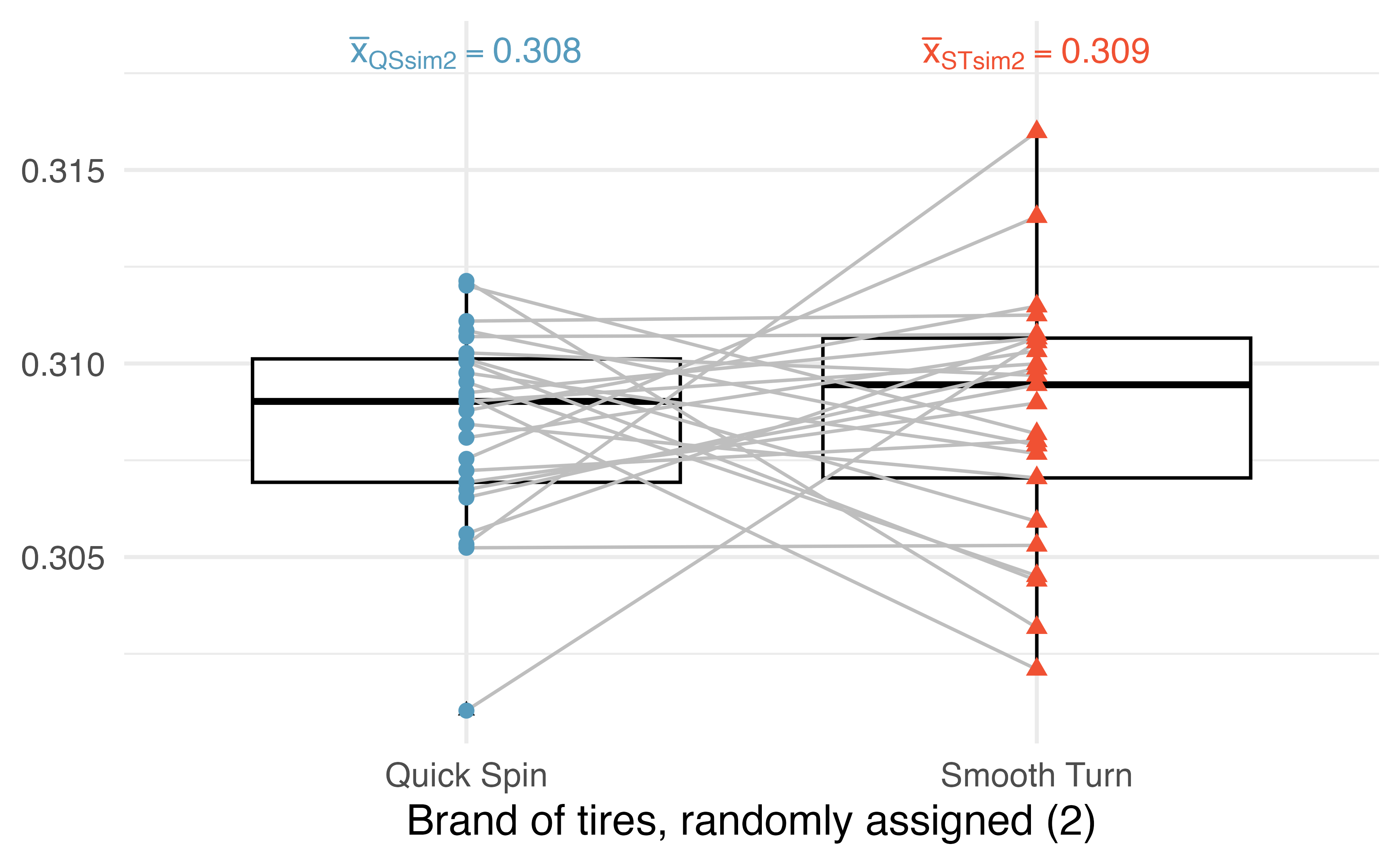
Figure 21.6: A second randomization where the brand is randomly swapped (or not) across the two tread wear measurements (in cm) from the same car.
Figure 21.7 presents yet another randomization of the data. Again, the same observations are linked by a grey line, and some of the tread values have been randomly assigned to the opposite tire brand than they were originally (while some are still connected to their original tire brands).
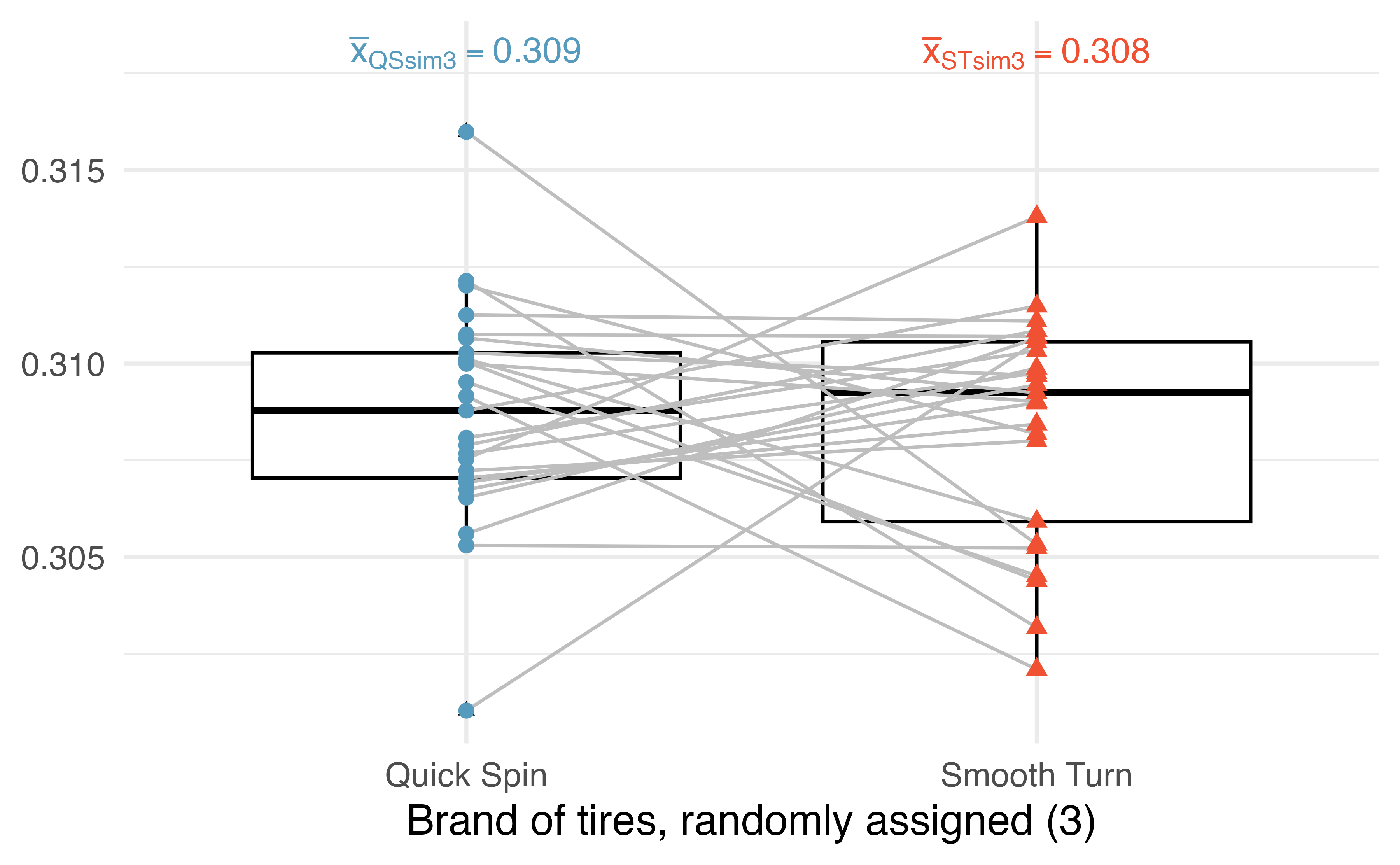
Figure 21.7: An additional randomization where the brand is randomly swapped (or not) across the two tread wear measurements (in cm) from the same car.
21.1.3 Observed statistic vs. null statistics
By repeating the randomization process, we can create a distribution of the average of the differences in tire treads, as seen in Figure 21.8. As expected (because the differences were generated under the null hypothesis), the center of the histogram is zero. A line has been drawn at the observed difference which is well outside the majority of the null differences simulated from natural variability by mixing up which the tire received Smooth Turn and which received Quick Spin. Because the observed statistic is so far away from the natural variability of the randomized differences, we are convinced that there is a difference between Smooth Turn and Quick Spin. Our conclusion is that the extra amount of average tire tread in Smooth Turn is due to more than just natural variability: we reject \(H_0\) and conclude that \(\mu_{ST} \ne \mu_{QS}.\)
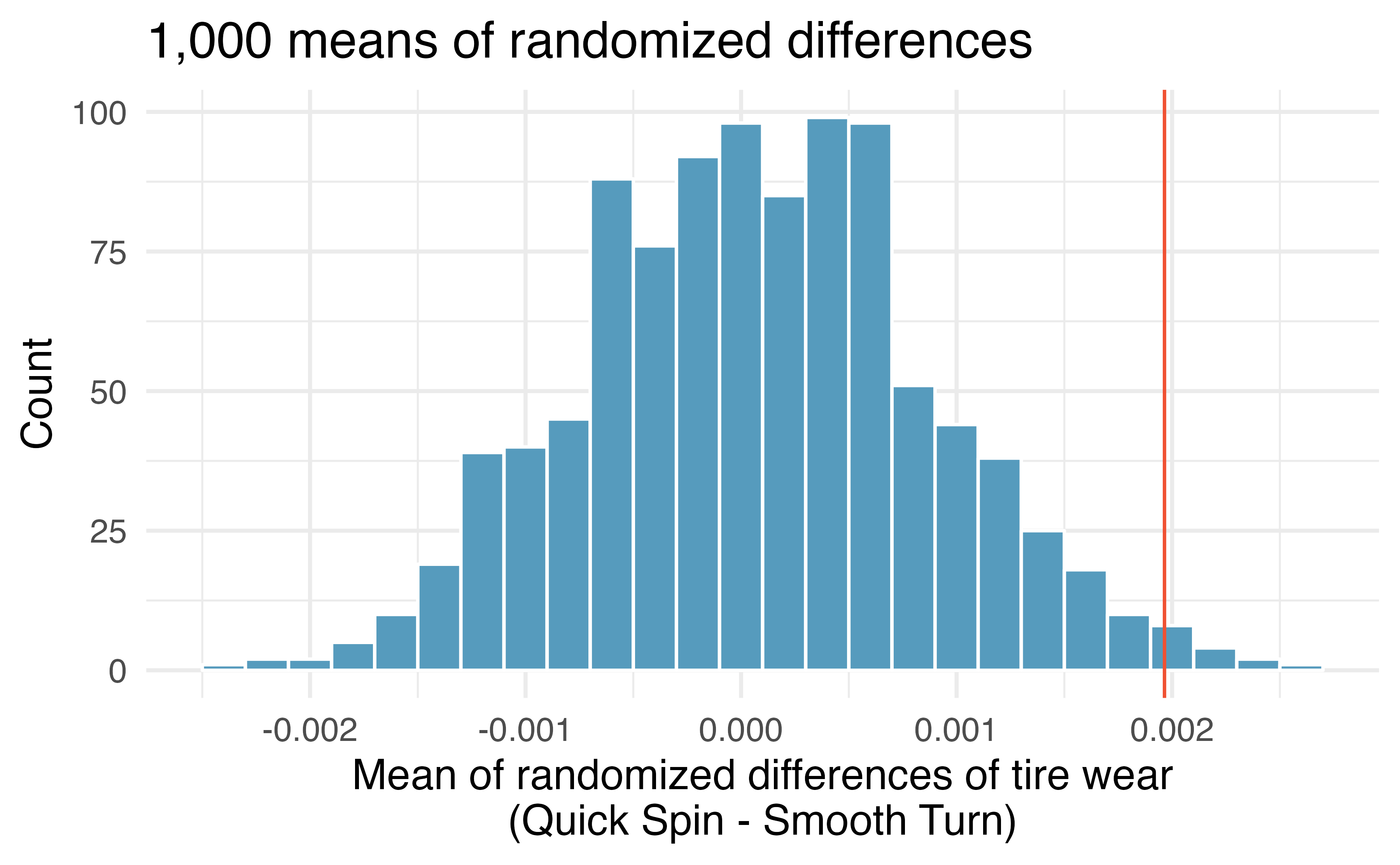
Figure 21.8: Histogram of 1,000 mean differences with tire brand randomly assigned across the two tread measurements (in cm) per pair.
21.2 Bootstrap confidence interval for the mean paired difference
For both the bootstrap and the mathematical models applied to paired data, the analysis is virtually identical to the one-sample approach given in Chapter 19. The key to working with paired data (for bootstrapping and mathematical approaches) is to consider the measurement of interest to be the difference in measured values across the pair of observations.
21.2.1 Observed data
In an earlier edition of this textbook, we found that Amazon prices were, on average, lower than those of the UCLA Bookstore for UCLA courses in 2010. It’s been several years, and many stores have adapted to the online market, so we wondered, how is the UCLA Bookstore doing today?
We sampled 201 UCLA courses. Of those, 68 required books could be found on Amazon. A portion of the dataset from these courses is shown in Figure 21.2, where prices are in US dollars.
The ucla_textbooks_f18 data can be found in the openintro R package.
| subject | course_num | bookstore_new | amazon_new | price_diff |
|---|---|---|---|---|
| American Indian Studies | M10 | 48.0 | 47.5 | 0.52 |
| Anthropology | 2 | 14.3 | 13.6 | 0.71 |
| Arts and Architecture | 10 | 13.5 | 12.5 | 0.97 |
| Asian | M60W | 49.3 | 55.0 | -5.69 |
Each textbook has two corresponding prices in the dataset: one for the UCLA Bookstore and one for Amazon. When two sets of observations have this special correspondence, they are said to be paired.
21.2.2 Variability of the statistic
Following the example of bootstrapping the one-sample statistic, the observed differences can be bootstrapped in order to understand the variability of the average difference from sample to sample. Remember, the differences act as a single value to bootstrap. That is, the original dataset would include the list of 68 price differences, and each resample will also include 68 price differences (some repeated through the bootstrap resampling process). The bootstrap procedure for paired differences is quite similar to the procedure applied to the one-sample statistic case in Section 19.1.
In Figure 21.9, two 99% confidence intervals for the difference in the cost of a new book at the UCLA bookstore compared with Amazon have been calculated. The bootstrap percentile confidence interval is computing using the 0.5 percentile and 99.5 percentile bootstrapped differences and is found to be ($0.25, $7.87).
Using the histogram of bootstrapped difference in means, estimate the standard error of the mean of the sample differences, \(\bar{x}_{diff}.\)206
The bootstrap SE interval is found by computing the SE of the bootstrapped differences \((SE_{\overline{x}_{diff}} = \$1.64)\) and the normal multiplier of \(z^* = 2.58.\) The averaged difference is \(\bar{x} = \$3.58.\) The 99% confidence interval is: \(\$3.58 \pm 2.58 \times \$ 1.64 = (\$-0.65, \$7.81).\)
The confidence intervals seem to indicate that the UCLA bookstore price is, on average, higher than the Amazon price, as the majority of the confidence interval is positive. However, if the analysis required a strong degree of certainty (e.g., 99% confidence), and the bootstrap SE interval was most appropriate (given a second course in statistics the nuances of the methods can be investigated), the results of which book seller is higher is not well determined (because the bootstrap SE interval overlaps zero). That is, the 99% bootstrap SE interval gives potential for UCLA to be lower, on average, than Amazon (because of the possible negative values for the true mean difference in price).
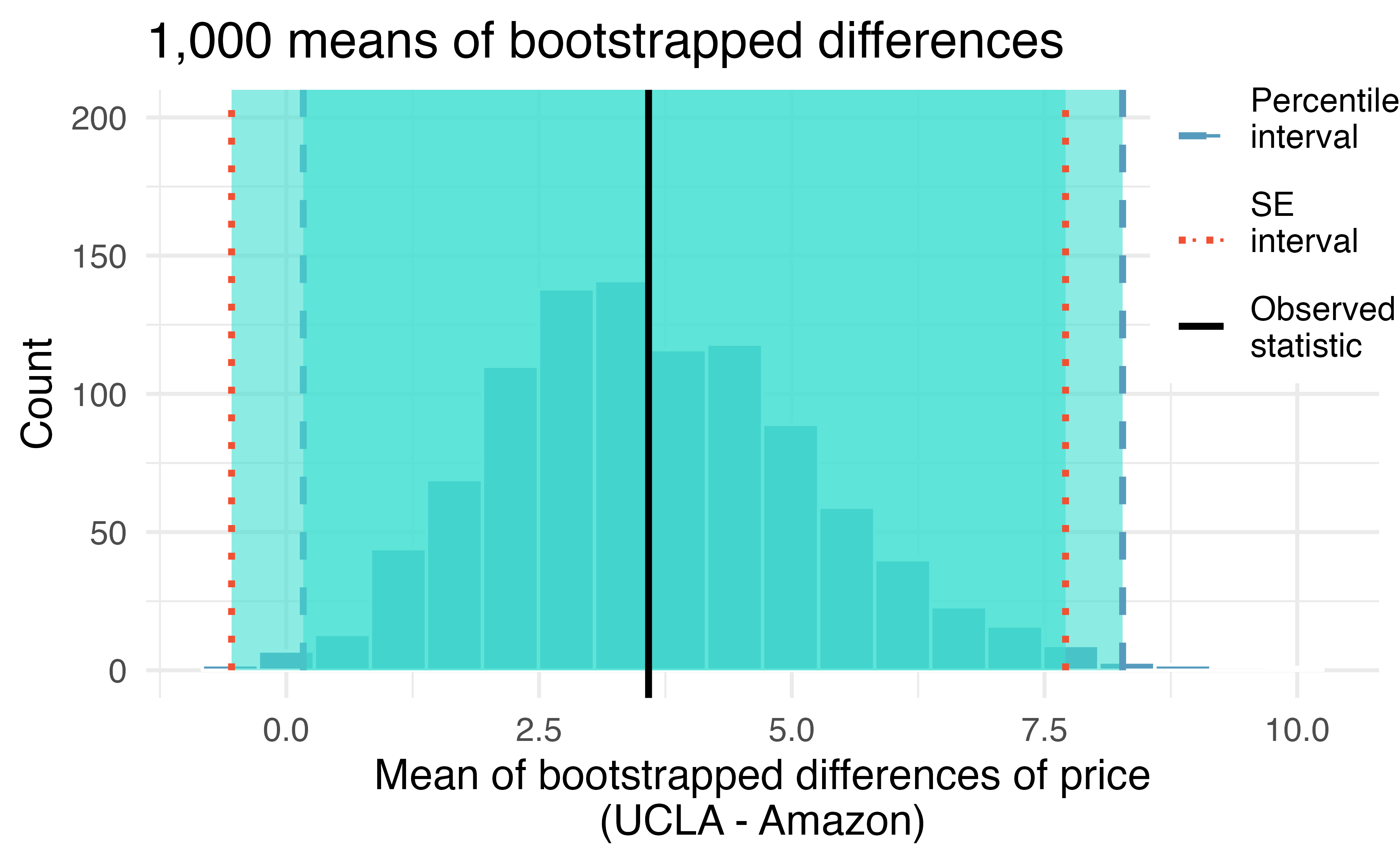
Figure 21.9: Bootstrap distribution for the average difference in new book price at the UCLA bookstore versus Amazon. 99% confidence intervals are superimposed using blue dashed (bootstrap percentile interval) and red dotted (bootstrap SE interval) lines.
21.3 Mathematical model for the mean paired difference
Thinking about the differences as a single observation on an observational unit changes the paired setting into the one-sample setting. The mathematical model for the one-sample case is covered in Section 19.2.
21.3.1 Observed data
To analyze paired data, it is often useful to look at the difference in outcomes of each pair of observations.
In the textbook data, we look at the differences in prices, which is represented as the price_difference variable in the dataset.
Here the differences are taken as
\[\text{UCLA Bookstore price} - \text{Amazon price}\]
It is important that we always subtract using a consistent order; here Amazon prices are always subtracted from UCLA prices. The first difference shown in Table 21.2 is computed as \(47.97 - 47.45 = 0.52.\) Similarly, the second difference is computed as \(14.26 - 13.55 = 0.71,\) and the third is \(13.50 - 12.53 = 0.97.\) A histogram of the differences is shown in Figure 21.10.
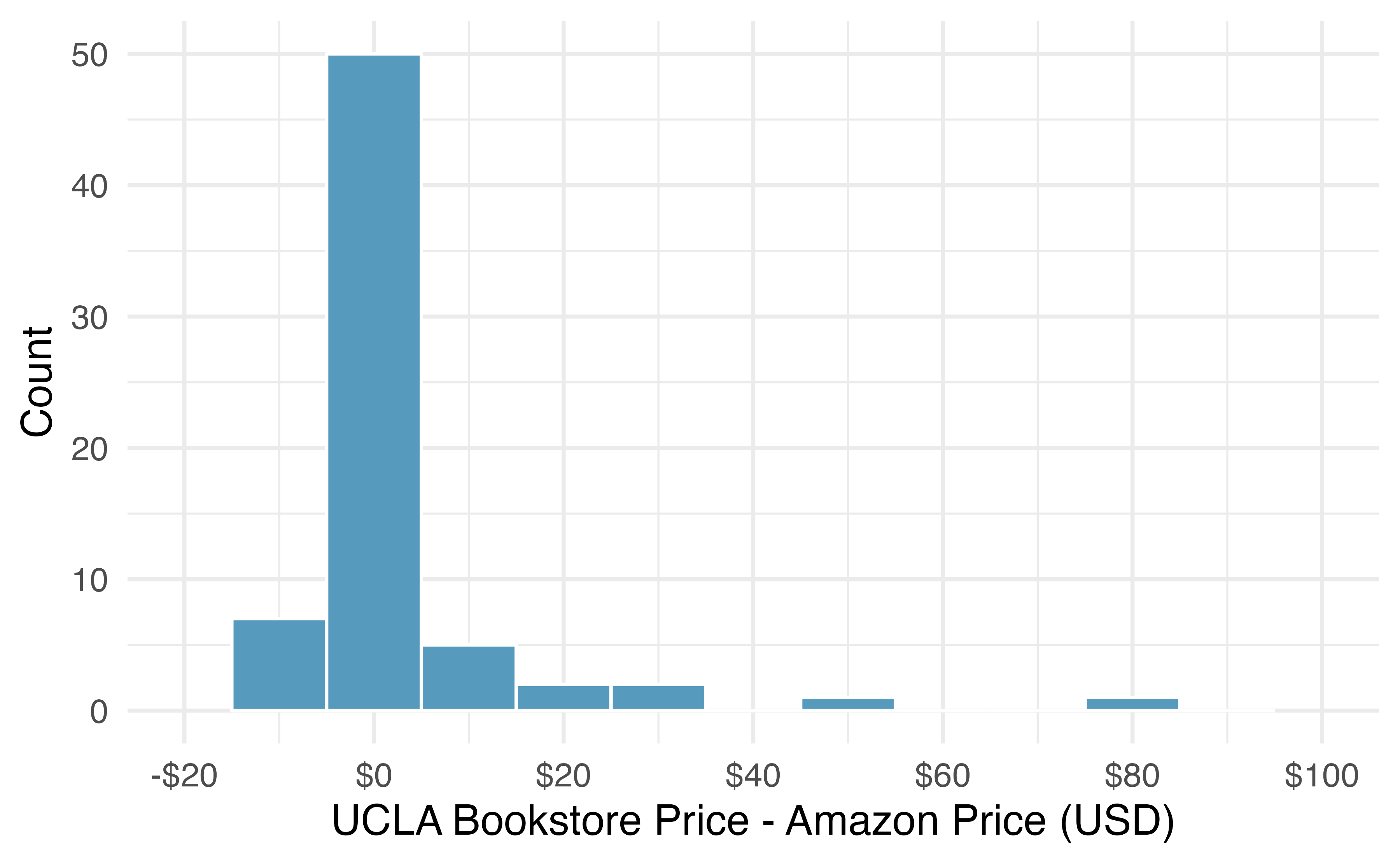
Figure 21.10: Histogram of the difference in price for each book sampled.
21.3.2 Variability of the statistic
To analyze a paired dataset, we simply analyze the differences. Table 21.3 provides the data summaries from the textbook data. Note that instead of reporting the prices separately for UCLA and Amazon, the summary statistics are given by the mean of the differences, the standard deviation of the differences, and the total number of pairs (i.e., differences). The parameter of interest is also a single value, \(\mu_{diff},\) so we can use the same \(t\)-distribution techniques we applied in Section 19.2 directly onto the observed differences.
| n | Mean | SD |
|---|---|---|
| 68 | 3.58 | 13.4 |
Set up a hypothesis test to determine whether, on average, there is a difference between Amazon’s price for a book and the UCLA bookstore’s price. Also, check the conditions for whether we can move forward with the test using the \(t\)-distribution.
We are considering two scenarios: there is no difference or there is some difference in average prices.
\(H_0:\) \(\mu_{diff} = 0.\) There is no difference in the average textbook price.
\(H_A:\) \(\mu_{diff} \neq 0.\) There is a difference in average prices.
Next, we check the independence and normality conditions. The observations are based on a simple random sample, so assuming the textbooks are independent seems reasonable. While there are some outliers, \(n = 68\) and none of the outliers are particularly extreme, so the normality of \(\bar{x}\) is satisfied. With these conditions satisfied, we can move forward with the \(t\)-distribution.
21.3.3 Observed statistic vs. null statistics
As mentioned previously, the methods applied to a difference will be identical to the one-sample techniques. Therefore, the full hypothesis test framework is presented as guided practices.
The test statistic for assessing a paired mean is a T.
The T score is a ratio of how the sample mean difference varies from zero as compared to how the observations vary.
\[T = \frac{\bar{x}_{diff} - 0 }{s_{diff}/\sqrt{n_{diff}}}\]
When the null hypothesis is true and the conditions are met, T has a t-distribution with \(df = n_{diff} - 1.\)
Conditions:
- Independently sampled pairs.
- Large samples and no extreme outliers.
Complete the hypothesis test started in the previous Example.
To compute the test compute the standard error associated with \(\bar{x}_{diff}\) using the standard deviation of the differences \((s_{diff} = 13.42)\) and the number of differences \((n_{diff} = 68):\)
\[SE_{\bar{x}_{diff}} = \frac{s_{diff}}{\sqrt{n_{diff}}} = \frac{13.42}{\sqrt{68}} = 1.63\]
The test statistic is the T score of \(\bar{x}_{diff}\) under the null condition that the actual mean difference is 0:
\[T = \frac{\bar{x}_{diff} - 0}{SE_{\bar{x}_{diff}}} = \frac{3.58 - 0}{1.63} = 2.20\]
To visualize the p-value, the sampling distribution of \(\bar{x}_{diff}\) is drawn as though \(H_0\) is true, and the p-value is represented by the two shaded tails in the figure below. The degrees of freedom is \(df = 68 - 1 = 67.\) Using statistical software, we find the one-tail area of 0.0156.
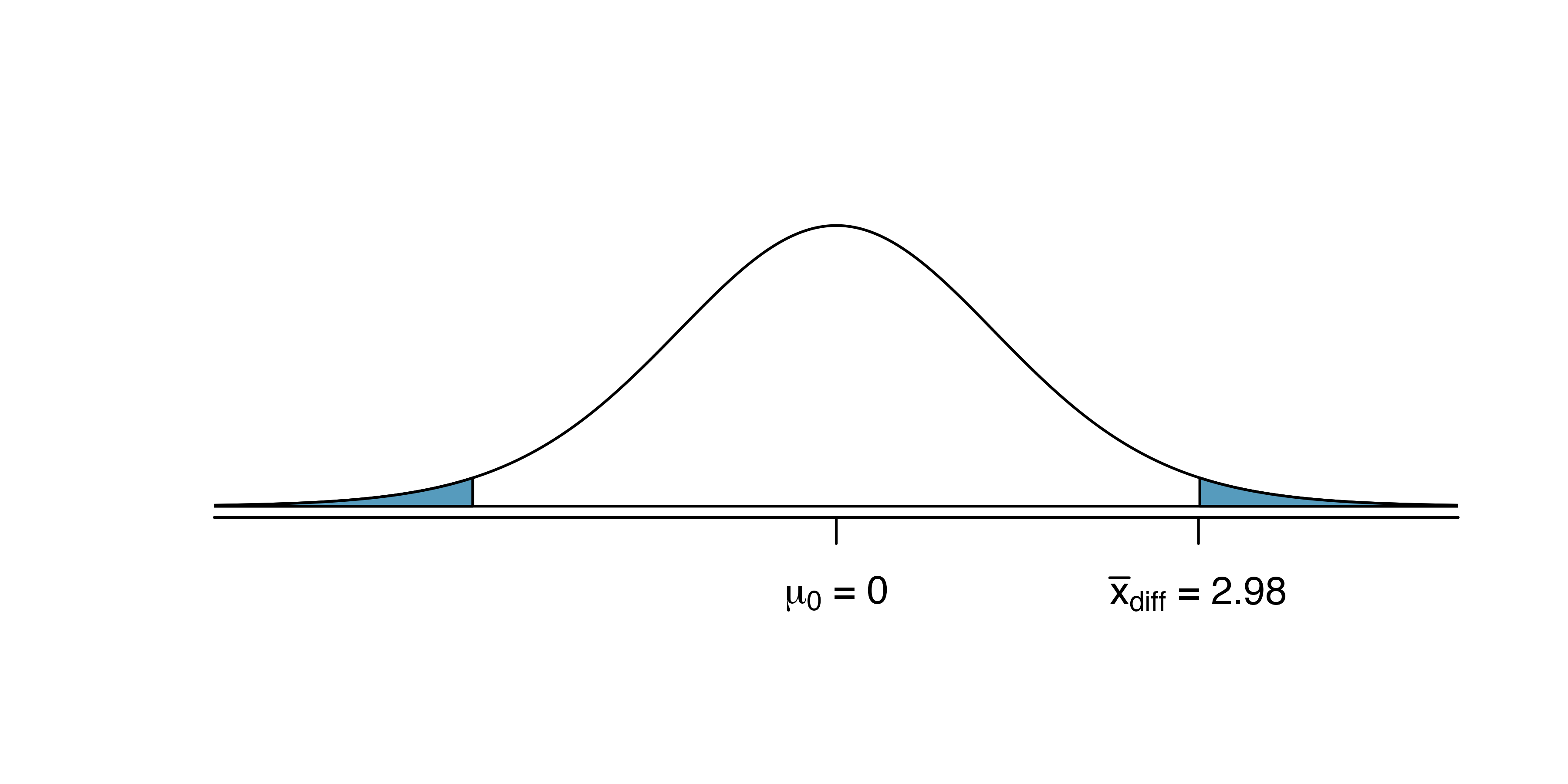
Doubling this area gives the p-value: 0.0312. Because the p-value is less than 0.05, we reject the null hypothesis. Amazon prices are, on average, lower than the UCLA Bookstore prices for UCLA courses.
Recall that the margin of error is defined by the standard error. The margin of error for \(\bar{x}_{diff}\) can be directly obtained from \(SE(\bar{x}_{diff}).\)
Margin of error for \(\bar{x}_{diff}.\)
The margin of error is \(t^\star_{df} \times s_{diff}/\sqrt{n_{diff}}\) where \(t^\star_{df}\) is calculated from a specified percentile on the t-distribution with df degrees of freedom.
Create a 95% confidence interval for the average price difference between books at the UCLA bookstore and books on Amazon.
Conditions have already verified and the standard error computed in a previous Example.
To find the confidence interval, identify \(t^{\star}_{67}\) using statistical software or the \(t\)-table \((t^{\star}_{67} = 2.00),\) and plug it, the point estimate, and the standard error into the confidence interval formula:
\[ \begin{aligned} \text{point estimate} \ &\pm \ z^{\star} \ \times \ SE \\ 3.58 \ &\pm \ 2.00 \ \times \ 1.63 \\ (0.32 \ &, \ 6.84) \end{aligned} \]
We are 95% confident that the UCLA Bookstore is, on average, between $0.32 and $6.84 more expensive than Amazon for UCLA course books.
We have convincing evidence that Amazon is, on average, less expensive. How should this conclusion affect UCLA student buying habits? Should UCLA students always buy their books on Amazon?207
21.4 Chapter review
21.4.1 Summary
Like the two independent sample procedures in Chapter 20, the paired difference analysis can be done using a t-distribution. The randomization test applied to the paired differences is slightly different, however. Note that when randomizing under the paired setting, each null statistic is created by randomly assigning the group to a numerical outcome within the individual observational unit. The procedure for creating a confidence interval for the paired difference is almost identical to the confidence intervals created in Chapter 19 for a single mean.
21.4.2 Terms
We introduced the following terms in the chapter. If you’re not sure what some of these terms mean, we recommend you go back in the text and review their definitions. We are purposefully presenting them in alphabetical order, instead of in order of appearance, so they will be a little more challenging to locate. However, you should be able to easily spot them as bolded text.
| bootstrap CI paired difference | paired difference CI | T score paired difference |
| paired data | paired difference t-test |
21.5 Exercises
Answers to odd numbered exercises can be found in Appendix A.21.
-
Air quality. Air quality measurements were collected in a random sample of 25 country capitals in 2013, and then again in the same cities in 2014. We would like to use these data to compare average air quality between the two years. Should we use a paired or non-paired test? Explain your reasoning.
-
True / False: paired. Determine if the following statements are true or false. If false, explain.
In a paired analysis we first take the difference of each pair of observations, and then we do inference on these differences.
Two datasets of different sizes cannot be analyzed as paired data.
Consider two sets of data that are paired with each other. Each observation in one dataset has a natural correspondence with exactly one observation from the other dataset.
Consider two sets of data that are paired with each other. Each observation in one dataset is subtracted from the average of the other dataset’s observations.
-
Paired or not? I. In each of the following scenarios, determine if the data are paired.
Compare pre- (beginning of semester) and post-test (end of semester) scores of students.
Assess gender-related salary gap by comparing salaries of randomly sampled men and women.
Compare artery thicknesses at the beginning of a study and after 2 years of taking Vitamin E for the same group of patients.
Assess effectiveness of a diet regimen by comparing the before and after weights of subjects.
-
Paired or not? II. In each of the following scenarios, determine if the data are paired.
We would like to know if Intel’s stock and Southwest Airlines’ stock have similar rates of return. To find out, we take a random sample of 50 days, and record Intel’s and Southwest’s stock on those same days.
We randomly sample 50 items from Target stores and note the price for each. Then we visit Walmart and collect the price for each of those same 50 items.
A school board would like to determine whether there is a difference in average SAT scores for students at one high school versus another high school in the district. To check, they take a simple random sample of 100 students from each high school.
-
Sample size and pairing. Determine if the following statement is true or false, and if false, explain your reasoning: If comparing means of two groups with equal sample sizes, always use a paired test.
-
High School and Beyond, randomization test. The National Center of Education Statistics conducted a survey of high school seniors, collecting test data on reading, writing, and several other subjects. Here we examine a simple random sample of 200 students from this survey. Side-by-side box plots of reading and writing scores as well as a histogram of the differences in scores are shown below. Also provided below is a histogram of randomized averages of paired differences of scores (read - write), with the observed difference (\(\bar{x}_{read-write} = -0.545\)) marked with a red vertical line. The randomization distribution was produced by doing the following 1000 times: for each student, the two scores were randomly assigned to either read or write, and the average was taken across all students in the sample.208
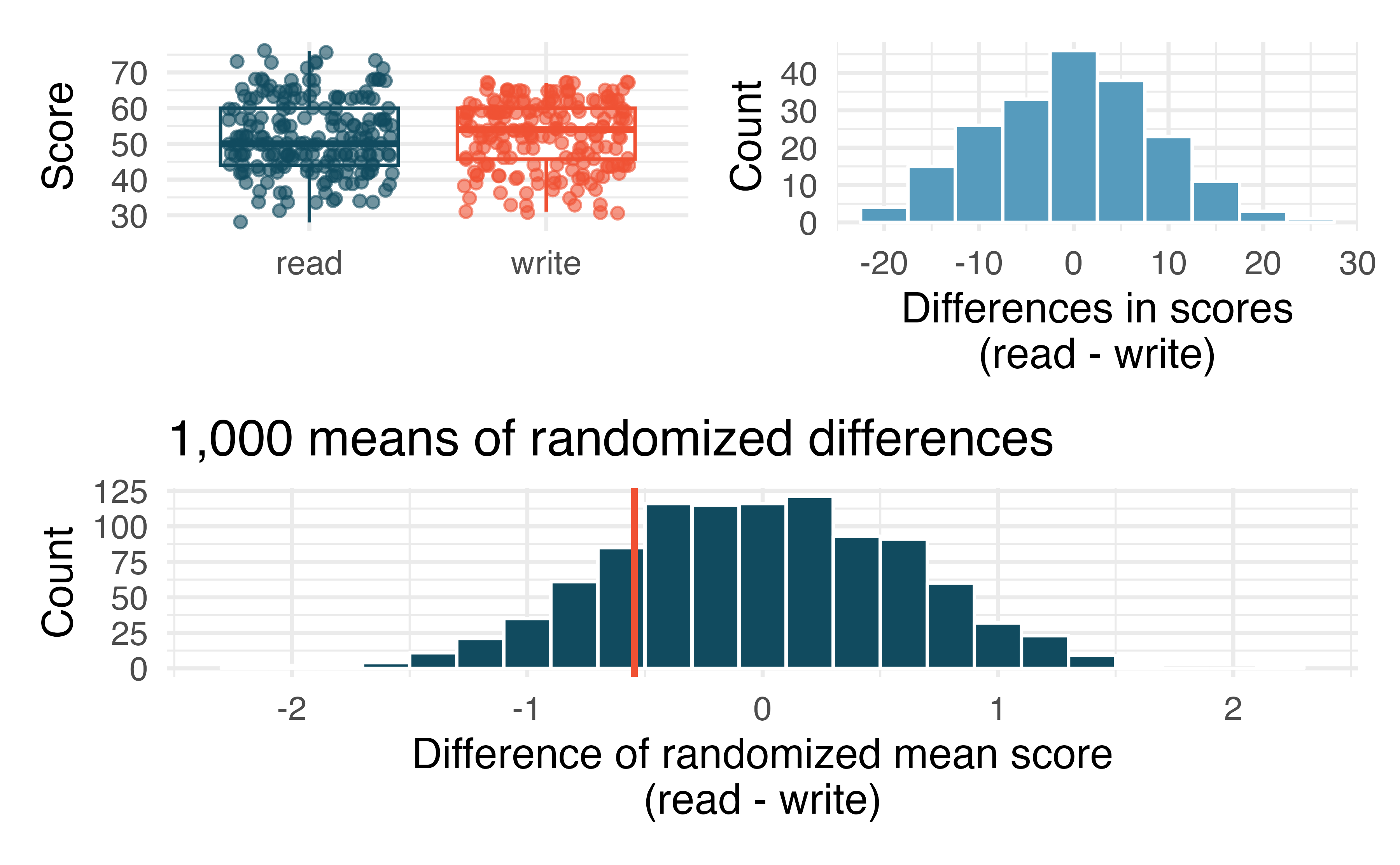
Is there a clear difference in the average reading and writing scores?
Are the reading and writing scores of each student independent of each other?
Create hypotheses appropriate for the following research question: is there an evident difference in the average scores of students in the reading and writing exam?
Is the average of the observed difference in scores \((\bar{x}_{read-write} = -0.545)\) consistent with the distribution of randomized average differences? Explain.
Do these data provide convincing evidence of a difference between the average scores on the two exams? Estimate the p-value from the randomization test, and conclude the hypothesis test using words like “score on reading test” and “score on writing test.”
-
Forest management. Forest rangers wanted to better understand the rate of growth for younger trees in the park. They took measurements of a random sample of 50 young trees in 2009 and again measured those same trees in 2019. The data below summarize their measurements, where the heights are in feet.
Year
Mean
SD
n
2009
12.0
3.5
50
2019
24.5
9.5
50
Difference
12.5
7.2
50
Construct a 99% confidence interval for the average growth of (what had been) younger trees in the park over 2009-2019.
-
High School and Beyond, bootstrap interval. We considered the differences between the reading and writing scores of a random sample of 200 students who took the High School and Beyond Survey. The mean and standard deviation of the differences are \(\bar{x}_{read-write} = -0.545\) and \(s_{read-write}\) = 8.887 points. The bootstrap distribution below was produced by bootstrapping from the sample of differences in reading and writing scores 1,000 times.
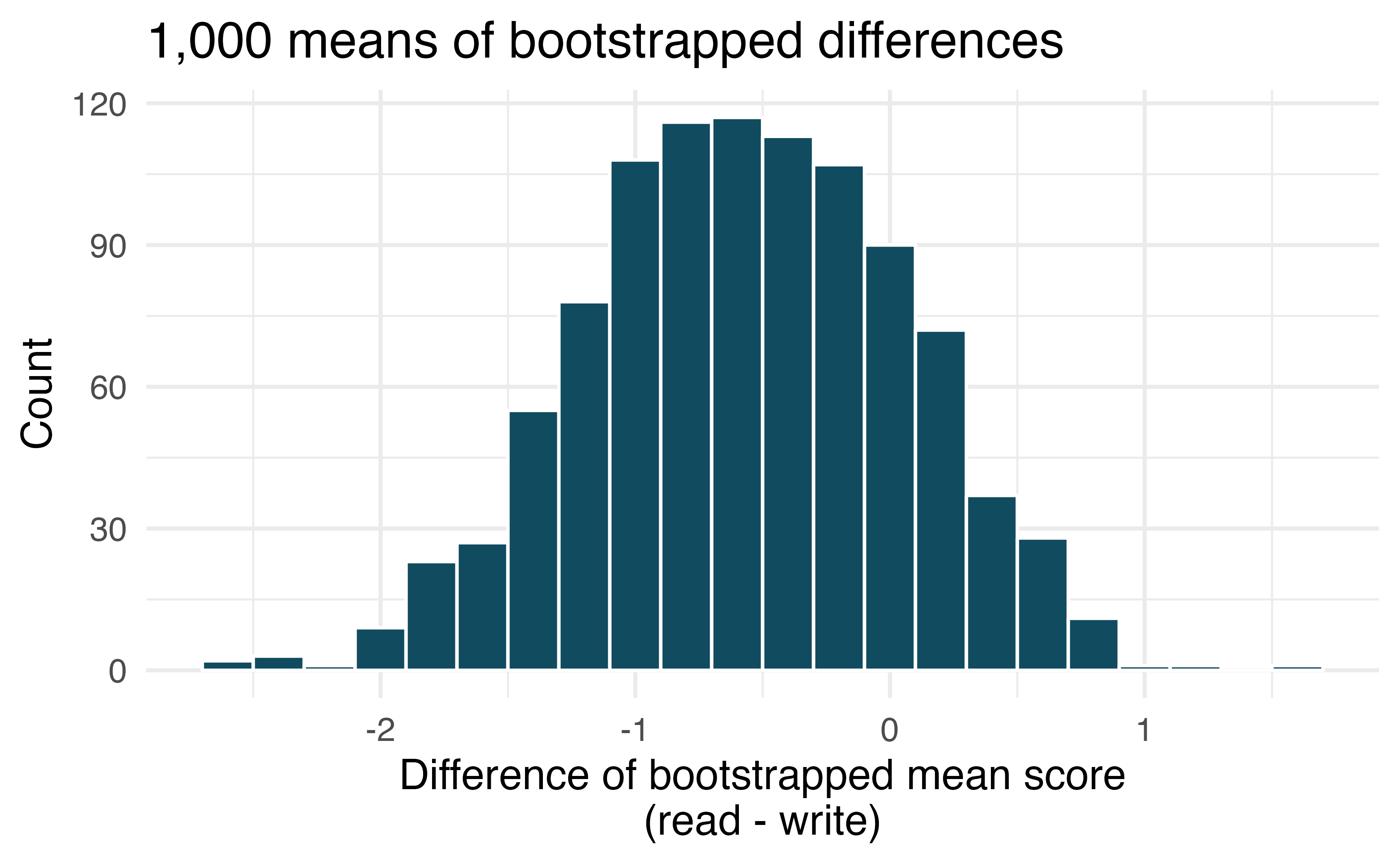
Find an approximate 95% bootstrap percentile confidence interval for the true average difference in scores (read - write).
Find an approximate 95% bootstrap SE confidence interval for the true average difference in scores (read - write).
Interpret both confidence intervals using words like “population” and “score.”
From the confidence intervals calculated above, does it appear that there is a significant difference in reading and writing scores, on average?
-
Possible paired randomized differences. Data were collected on five people.
Person 1
Person 2
Person 3
Person 4
Person 5
Observation 1
3
14
4
5
10
Observation 2
7
3
6
5
9
Difference
-4
11
-2
0
1
Which of the following could be a possible randomization of the paired differences given above? If the set of values could not be a randomized set of differences, indicate why not.
-2, 1, 1, 11, -2
-4 11 -2 0 1
-2, 2, -11, 11, -2, 2, 0, 1, -1
0, -1, 2, -4, 11
4, -11, 2, 0, -1
-
Study environment. In order to test the effects of listening to music while studying versus studying in silence, students agree to be randomized to two treatments (i.e., study with music or study in silence). There are two exams during the semester, so the researchers can either randomize the students to have one exam with music and one with silence (randomly selecting which exam corresponds to which study environment) or the researchers can randomize the students to one study habit for both exams.
The researchers are interested in estimating the true population difference of exam score for those who listen to music while studying as compared to those who study in silence.
Describe the experiment which is consistent with a paired designed experiment. How is the treatment assigned, and how are the data collected such that the observations are paired?
Describe the experiment which is consistent with an indpenedent samples experiment. How is the treatment assigned, and how are the data collected such that the observations are independent?
-
Global warming, randomization test. Let’s consider a limited set of climate data, examining temperature differences in 1948 vs 2018. We sampled 197 locations from the National Oceanic and Atmospheric Administration’s (NOAA) historical data, where the data was available for both years of interest. We want to know: were there more days with temperatures exceeding 90F in 2018 or in 1948? (NOAA 2018) The difference in number of days exceeding 90F (number of days in 2018 - number of days in 1948) was calculated for each of the 197 locations. The average of these differences was 2.9 days with a standard deviation of 17.2 days. We are interested in determining whether these data provide strong evidence that there were more days in 2018 that exceeded 90F from NOAA’s weather stations.209
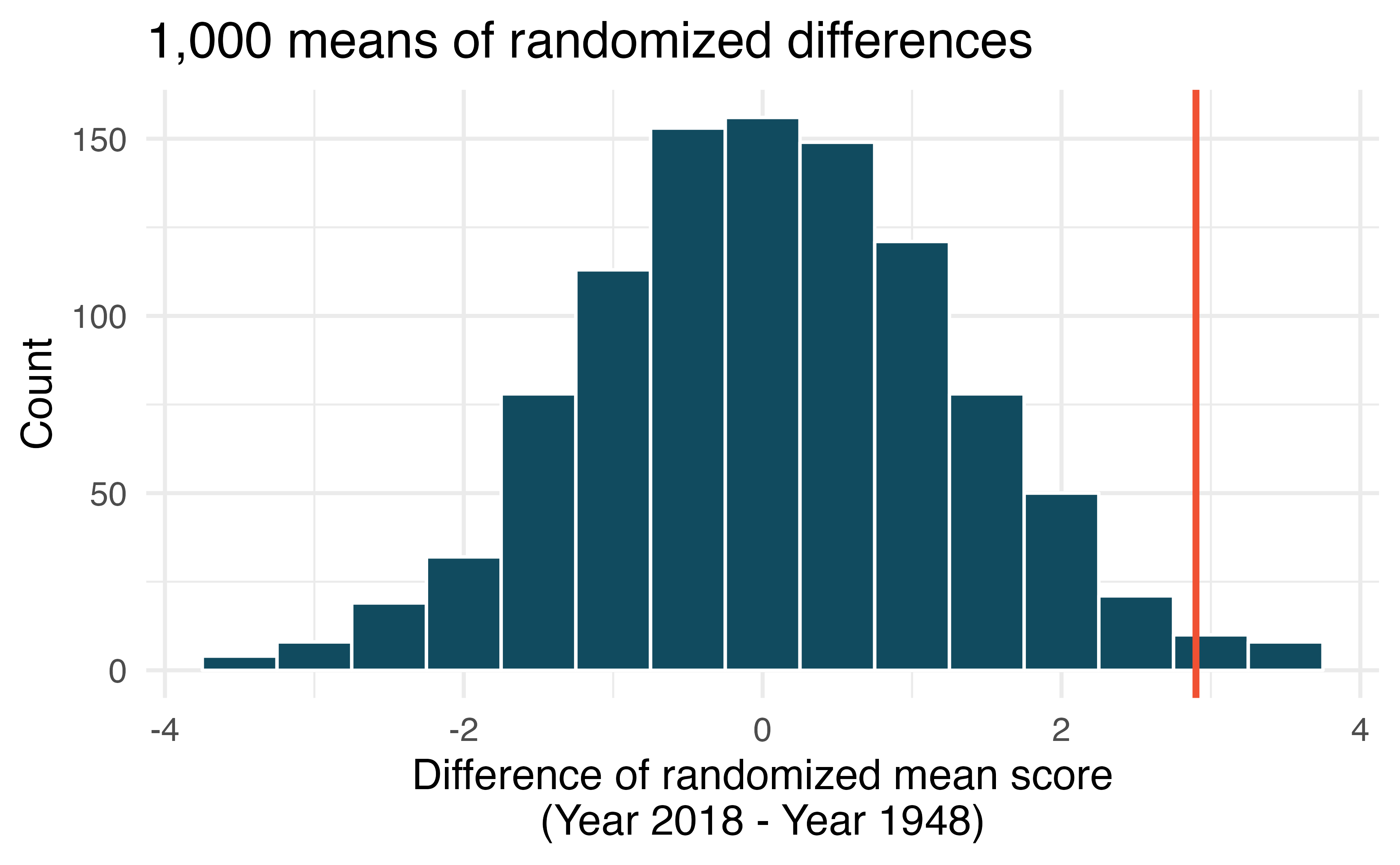
Create hypotheses appropriate for the following research question: is there an evident difference in the average number of days greater than 90F across the two years (1948 and 2018)?
Is the average of the observed difference in scores \((\bar{x}_{2018-1948} = 2.9)\) consistent with the distribution of randomized average differences? Explain.
Do these data provide convincing evidence of a difference between the average number of days? Estimate the p-value from the randomization test, and conclude the hypothesis test using words like “number of days in 1948” and “number of days in 2018.”
-
Global warming, bootstrap interval. We considered the change in the number of days exceeding 90F from 1948 and 2018 at 197 randomly sampled locations from the NOAA database. The mean and standard deviation of the reported differences are 2.9 days and 17.2 days.
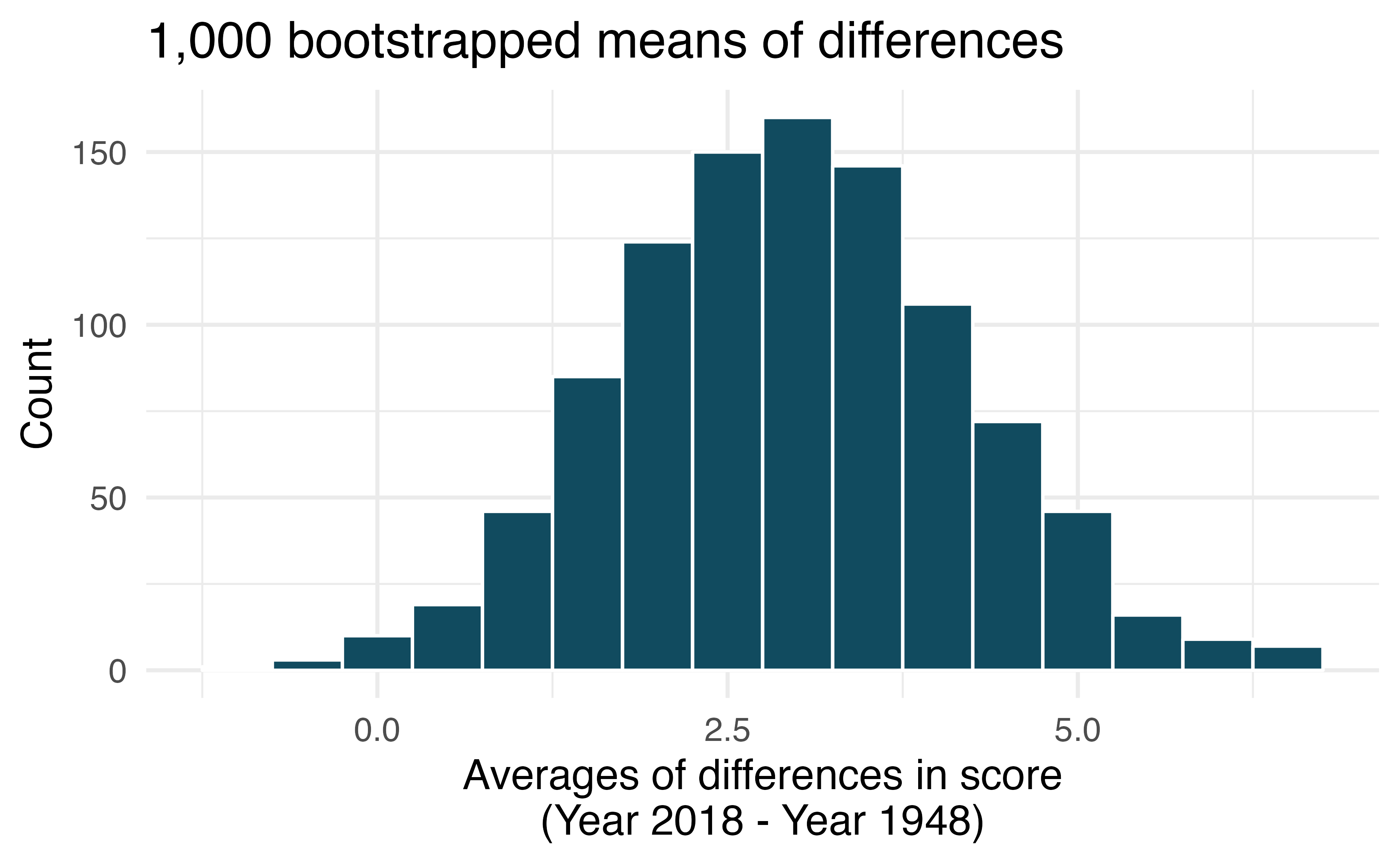
Calculate a 90% bootstrap percentile confidence interval for the average difference between number of days exceeding 90F between 1948 and 2018.
Calculate a 90% bootstrap SE confidence interval for the average difference between number of days exceeding 90F between 1948 and 2018.
Interpret both intervals in context.
Do the confidence intervals provide convincing evidence that there were more days exceeding 90F in 2018 than in 1948 at NOAA stations? Explain your reasoning.
-
Global warming, mathematical test. We considered the change in the number of days exceeding 90F from 1948 and 2018 at 197 randomly sampled locations from the NOAA database. The mean and standard deviation of the reported differences are 2.9 days and 17.2 days.
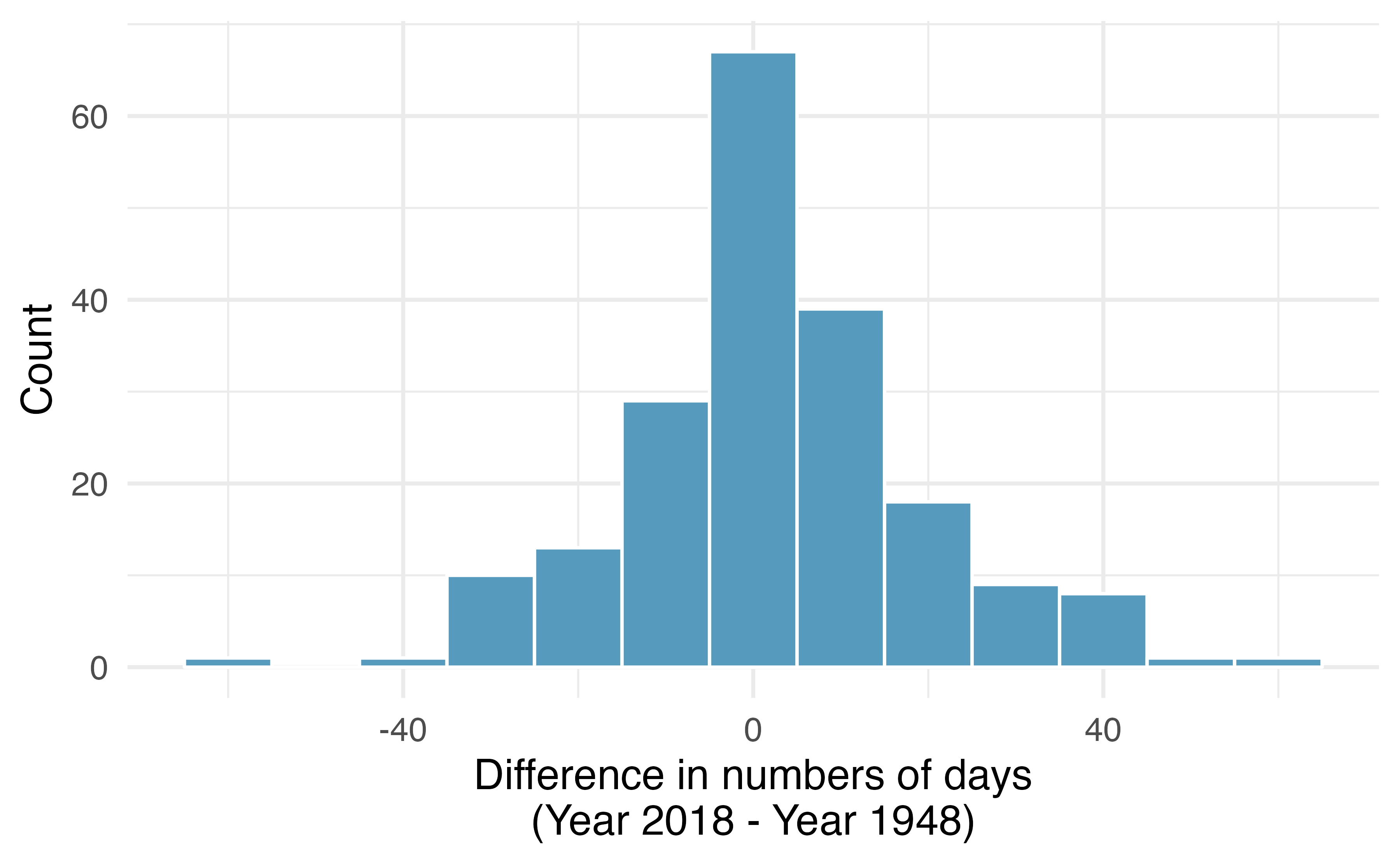
Is there a relationship between the observations collected in 1948 and 2018? Or are the observations in the two groups independent? Explain.
Write hypotheses for this research in symbols and in words.
Check the conditions required to complete this test. A histogram of the differences is given to the right.
Calculate the test statistic and find the p-value.
Use \(\alpha = 0.05\) to evaluate the test, and interpret your conclusion in context.
What type of error might we have made? Explain in context what the error means.
Based on the results of this hypothesis test, would you expect a confidence interval for the average difference between the number of days exceeding 90F from 1948 and 2018 to include 0? Explain your reasoning.
-
High School and Beyond, mathematical test. We considered the differences between the reading and writing scores of a random sample of 200 students who took the High School and Beyond Survey.
Create hypotheses appropriate for the following research question: is there an evident difference in the average scores of students in the reading and writing exam?
Check the conditions required to complete this test.
The average observed difference in scores is \(\bar{x}_{read-write} = -0.545\), and the standard deviation of the differences is \(s_{read-write} = 8.887\) points. Do these data provide convincing evidence of a difference between the average scores on the two exams?
What type of error might we have made? Explain what the error means in the context of the application.
Based on the results of this hypothesis test, would you expect a confidence interval for the average difference between the reading and writing scores to include 0? Explain your reasoning.
-
Global warming, mathematical interval. We considered the change in the number of days exceeding 90F from 1948 and 2018 at 197 randomly sampled locations from the NOAA database. The mean and standard deviation of the reported differences are 2.9 days and 17.2 days.
Calculate a 90% confidence interval for the average difference between number of days exceeding 90F between 1948 and 2018. We’ve already checked the conditions for you.
Interpret the interval in context.
Does the confidence interval provide convincing evidence that there were more days exceeding 90F in 2018 than in 1948 at NOAA stations? Explain your reasoning.
-
High school and beyond, mathematical interval. We considered the differences between the reading and writing scores of a random sample of 200 students who took the High School and Beyond Survey. The mean and standard deviation of the differences are \(\bar{x}_{read-write} = -0.545\) and \(s_{read-write}\) = 8.887 points.
Calculate a 95% confidence interval for the average difference between the reading and writing scores of all students.
Interpret this interval in context.
Does the confidence interval provide convincing evidence that there is a real difference in the average scores? Explain.
-
Friday the 13th, traffic. In the early 1990’s, researchers in the UK collected data on traffic flow on Friday the 13th with the goal of addressing issues of how superstitions regarding Friday the 13th affect human behavior and and whether Friday the 13th is an unlucky day. The histograms below show the distributions of numbers of cars passing by a specific intersection on Friday the 6th and Friday the 13th for many such date pairs. Also provided are some sample statistics, where the difference is the number of cars on the 6th minus the number of cars on the 13th.210 (Scanlon et al. 1993)
n
Mean
SD
sixth
10
128,385
7,259
thirteenth
10
126,550
7,664
diff
10
1,836
1,176
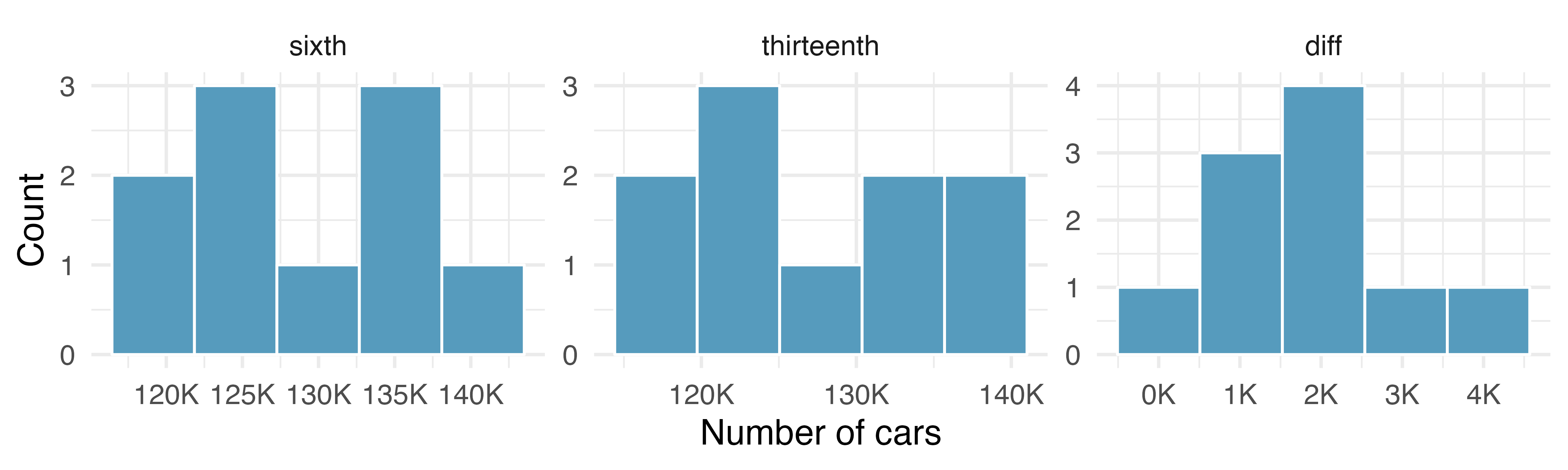
Are there any underlying structures in these data that should be considered in an analysis? Explain.
What are the hypotheses for evaluating whether the number of people out on Friday the 6\(^{\text{th}}\) is different than the number out on Friday the 13\(^{\text{th}}\)?
Check conditions to carry out the hypothesis test from part (b) using mathematical models.
Calculate the test statistic and the p-value.
What is the conclusion of the hypothesis test?
Interpret the p-value in this context.
What type of error might have been made in the conclusion of your test? Explain.
-
Friday the 13th, accidents. In the early 1990’s, researchers in the UK collected data the number of traffic accident related emergency room (ER) admissions on Friday the 13th with the goal of addressing issues of how superstitions regarding Friday the 13th affect human behavior and and whether Friday the 13th is an unlucky day. The histograms below show the distributions of numbers of ER admissions at specific emergency rooms on Friday the 6th and Friday the 13th for many such date pairs. Also provided are some sample statistics, where the difference is the ER admissions on the 6th minus the ER admissions on the 13th.(Scanlon et al. 1993)
n
Mean
SD
sixth
6
8
3
thirteenth
6
11
4
diff
6
-3
3
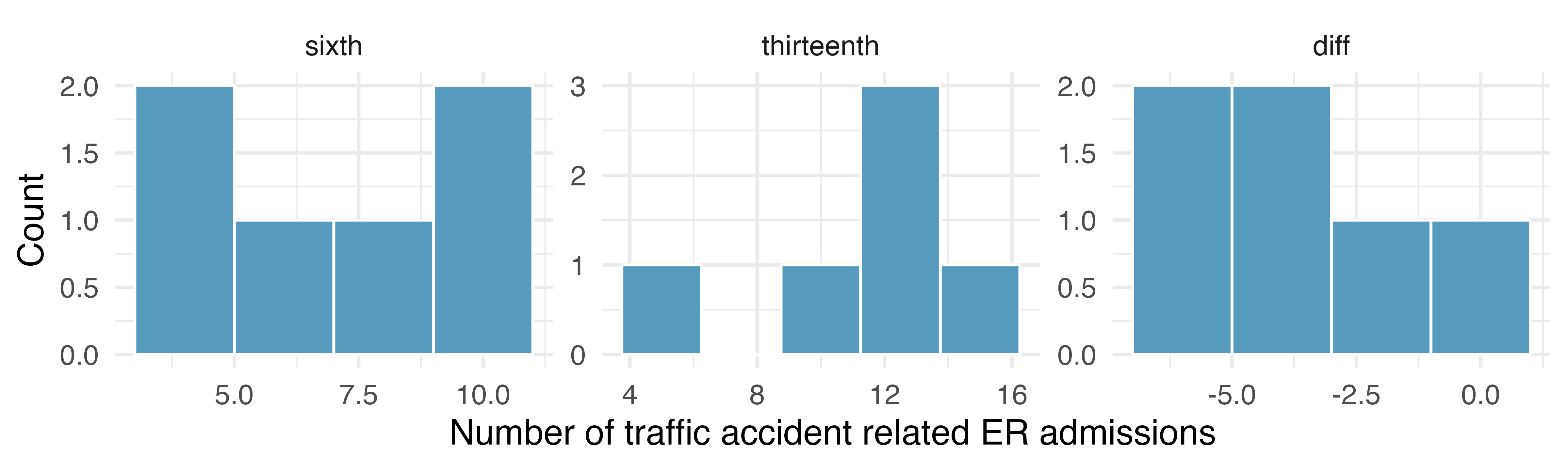
Conduct a hypothesis test using mathematical models to evaluate if there is a difference between the average numbers of traffic accident related emergency room admissions between Friday the 6\(^{\text{th}}\) and Friday the 13\(^{\text{th}}\).
Calculate a 95% confidence interval using mathematical models for the difference between the average numbers of traffic accident related emergency room admissions between Friday the 6\(^{\text{th}}\) and Friday the 13\(^{\text{th}}\).
The conclusion of the original study states, “Friday 13th is unlucky for some. The risk of hospital admission as a result of a transport accident may be increased by as much as 52%. Staying at home is recommended.” Do you agree with this statement? Explain your reasoning.